
研究成果
实验室CUDA-NPU编译器成果获CGO 2026杰出论文奖,并发表多篇论文
2026年初,“IEEE/ACM国际代码生成与优化研讨会”(IEEE/ACM International Symposium on Code Generation and Optimization,CGO)在澳大利亚召开。CGO是编译领域的顶级国际会议之一,主要关注代码生成与优化,包括纯软件的动静态编译优化和代码生成以及软硬件协同相关技术。处理器芯片全国重点实验室论文《From Threads to Tiles: T2T, a Compiler for CUDA-to-NPU Translation via 2D Vectorization》被CGO 2026接收,并获得杰出论文奖。该论文第一作者为实验室编译组博士生李帅江,指导教师为赵家程副研究员和崔慧敏研究员。
在 AI 与高性能计算领域,CUDA 凭借 SIMT(单指令多线程)编程模型成为 GPU 通用计算的基础,支撑着科学模拟、数据分析、深度学习等海量并行计算工作。然而,以谷歌 TPU、华为昇腾、寒武纪思元为代表的 NPU(神经网络处理器)正快速崛起,其基于粗粒度 2D 分块指令的架构,在能效比和密集型计算性能上优势显著。
然而,NPU的硬件架构与GPU有根本性不同,两者间存在巨大语义鸿沟:CUDA 依赖隐式标量线程并行,而 NPU 需要显式 2D 张量指令,直接迁移面临 “从线程到分块” 的本质难题 —— 不仅要重构执行模型,还需满足 NPU 严格的内存对齐与数据布局约束,手动改写成本极高,成为 CUDA 生态向 NPU 迁移的关键瓶颈。
T2T 编译器框架的核心突破的是通过系统性 2D 向量化技术,自动化完成这一复杂迁移:
- 1.提出统一并行抽象(UPA)。T2T首先将CUDA内核中由网格、线程块、线程束和线程构成的复杂并行层次结构,系统性地转换为一套显式的、无循环依赖的嵌套循环。UPA单元的关键在于捕获了CUDA的“所有线程并行执行”这一核心语义,使得原本隐含的并行模式变得可被编译器分析和操作,是向量化处理与优化的最小单位
- 2.2D 分块向量化引擎。与传统的、通常只针对最内层循环的一维向量化不同,T2T的向量化引擎需要协同分析UPA单元中的多个循环维度。它首先对每个循环维度的内存访问模式进行分类分析,然后基于NPU硬件的严格对齐约束,寻找能够合法且高效组合成单个NPU二维指令的循环对并映射到 NPU 硬件指令,提高硬件利用率;
- 3.语义保持的针对性优化。控制流简化:通过常量传播等优化,尽可能消除由线程索引条件产生的昂贵掩码操作,将其转换为无条件向量指令。语义制导的Warp原语优化:通过捕捉CUDA Warp 级并行语义,适配 NPU 2D 张量指令架构,在保障迁移后语义正确性的前提下,进一步提升硬件计算利用率。
- 4.多平台后端支持:基于MLIR设计了两层中间表示,高层IR保持硬件无关的语义,低层IR对接具体NPU平台(如华为昇腾、寒武纪),实现了良好的可扩展性和平台特定优化能力。
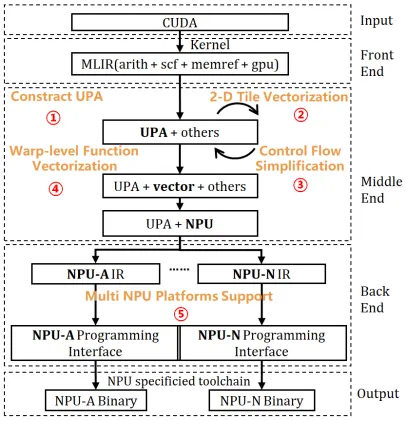
图1 T2T编译流程图
实测显示,T2T 翻译的内核在 NPU 上最高可达 A100 GPU 原生硬件利用率的 73%,较传统 1D 向量化方案提速 6.9 倍,成功覆盖 Rodinia 基准测试与 65 个 AI 核心算子。这一编译器驱动的解决方案,为 CUDA 庞大生态向高效 NPU 加速器迁移提供了低成本、高性能的可行路径,加速异构计算硬件的普及应用。
喜事多多
《Progressive Low-Precision Approximation of Tensor Operators on GPUs: Enabling Greater Trade-Offs between Performance and Accuracy》,该论文被CGO 2026录用,第一作者为实验室博士生罗凡,指导教师为李广力副研究员,该研究主要面向低精度张量算子调优。
《DyPARS: Dynamic-Shape DNN Optimization via Pareto-Aware MCTS for Graph Variants》,该论文与新南威尔士大学联合发表,被CGO2026录用,实验室李广力副研究员为共同通讯作者,该研究主要面向动态shape计算图优化,获得Distinguished Artifact Award
《PriTran: Privacy-Preserving Inference for Transformer-Based Language Models under Fully Homomorphic Encryption》,该论文与新南威尔士大学联合发表,被CGO2026录用,实验室李广力副研究员为共同通讯作者,该研究主要面向FHE Transformer程序优化。